[C#] XMLをXPathを利用してデータを取得する方法
こんにちは。明月です。
この投稿はC#でXMLをXPathを利用してデータを取得する方法に関する説明です。
以前、XMLをCssSelectorエンジン(Sizzle)みたいに要素を検索してデータを取得する方法に関して説明したことがあります。
link - [C#] NSoupライブラリを利用してXMLとHTMLをパーシングする方法
最近はXPathを利用して検索することよりNSoupのライブラリを利用してデータを取得することが一般的なことになりました。でも、Sizzleエンジンの要素を検索する方法の以前はXPathで検索することが一般的だったんです。
でも、XPathの方法が悪いことではなく、Css Selectorで検索するキーが単純だし、理解しやすいのでよく使うことです。でも以前の方法がもっとよい時があります。
例えば、XMLから一つのデータとノードを検索することではNSoupのほうがいいです。でも、XMLの全体を構造化するしクラスを変換することではReaderを利用するかもっと明確なルールを決めて検索することならXPathがよいです。
Stringで正規表現でReplaceするか、ただ特定文字でReplaceするかの差と似てます。
実はXPathを使うためにはXPathを詳しく知らなければならないですが、いつかXPathは別途で説明します。
XPathを使うために以前で使った私のブログの検索エンジンに登録するようなRSSファイルを使いましょう。

link - https://www.nowonbun.com/rss
XPathを利用するクラスのNSoupみたいにオープンソースではなく、System.XMLの.Net Frameworkを使います。
using System;
// XmlDocumentを使うためのNamespace
using System.Xml;
namespace Example
{
class Program
{
// 実行関数
static void Main(string[] args)
{
// XmlDocumentを宣言
XmlDocument xmlDoc = new XmlDocument();
// rssを取得する。 urlアドレスならHttpの通信で取得する。ローカルディレクトならローカルで取得する。
xmlDoc.Load("https://www.nowonbun.com/rss");
// rssタグの下の channelタグの下の itemタグを選択
XmlNodeList itemNodes = xmlDoc.SelectNodes("//rss/channel/item");
// そのタグを複数なので繰り返しで探索する。
foreach (XmlNode itemNode in itemNodes)
{
// itemタグの下でtitleタグを選択
XmlNode titleNode = itemNode.SelectSingleNode("title");
// タグの値をコンソールに出力
Console.WriteLine(titleNode.InnerText);
// itemタグの下でdescriptionタグを選択
titleNode = itemNode.SelectSingleNode("description");
// Hello worldで書き直す。
titleNode.InnerText = "Hello world";
}
// ファイルで格納する。
xmlDoc.Save("c://work//rss.xml");
Console.WriteLine("Press any key...");
Console.ReadKey();
}
}
}
コンソールの結果をみればrssのtitleのタグの内容だけ出力したことを確認できます。
後、descriptionのタグのテキストデータを変更して、ファイルに格納しました。
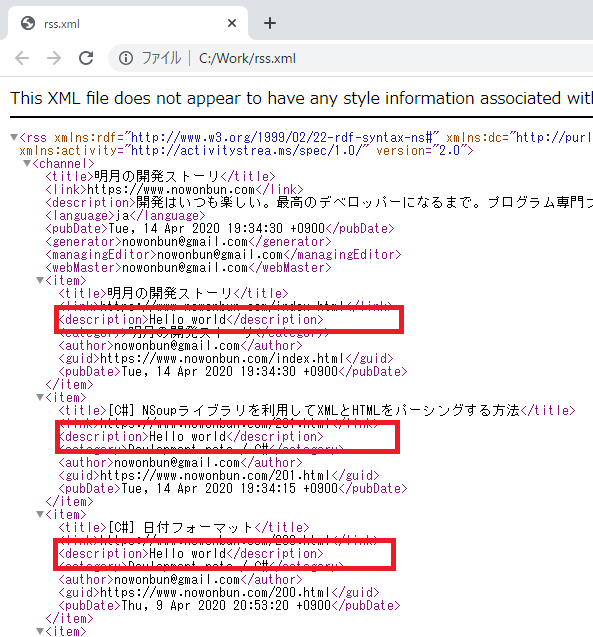
結果を確認すればdescriptionタグの内容が変更されたことを確認できます。
NSoupとSystem.Xmlの差はNSoupの場合はHtmlまで検索ができます。でも、System.Xmlの場合はHtmlファイルが検索ができません。
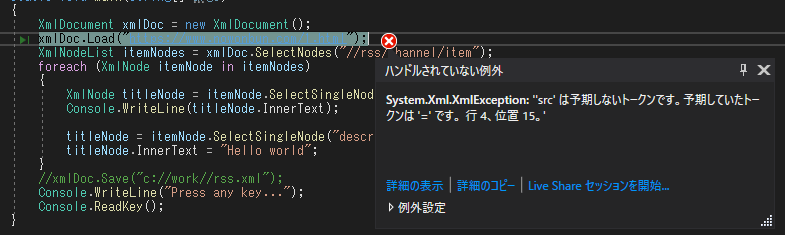
Htmlを読み込めば許せないアトリビュートや開き閉めタグタイプではないこと(inputタグ)などでエラーが発生します。
個人的にはほぼNSoupを使いますが、逆に環境ファイルのXMLの場合は厳しい構造を要求するので逆にSystem.Xmlをよく使います。
ここまでC#でXMLをXPathを利用してデータを取得する方法に関する説明でした。
ご不明なところや間違いところがあればコメントしてください。
- [C#] dynamicタイプの動的パラメータ-DynamicObject(WinFormでASP.MVCのViewBagオブジェクトを使用する方法)2020/04/29 22:41:32
- [C#] Stringの補間式(interpolation)2020/04/27 20:39:57
- [C#] Newtonsoft.JSONライブラリを利用してJsonデータ構造を扱う方法2020/04/23 20:19:53
- [C#] EMailを送信する方法(System.Net.Mail)2020/04/22 19:00:42
- [C#] ini環境ファイルを使う方法2020/04/22 00:09:39
- [C#] 環境設定ファイルを扱う方法(System.Configuration)2020/04/20 19:37:57
- [C#] Reflectionを利用してクラス複製する方法2020/04/17 00:34:33
- [C#] XMLをXPathを利用してデータを取得する方法2020/04/16 00:47:17
- [C#] NSoupライブラリを利用してXMLとHTMLをパーシングする方法2020/04/14 19:34:15
- [C#] 日付フォーマット2020/04/09 20:53:20
- [C#] ログライブラリ(log4net)を設定する方法2020/04/08 13:04:22
- [C#] Zipの圧縮ファイルを解凍するコードを作成する方法2020/04/07 11:17:44
- [C#] Zip圧縮コードを作成する方法2020/04/06 14:56:13
- [C#] 数字フォーマット(お金表示及び小数点以下表示)2020/04/03 00:38:37
- [C#] コマンド(cmd)を実行する方法(Processクラス)2020/03/31 07:15:40
- check2024/04/10 19:03:53
- [Java] 64.Spring bootとReactを連結する方法(Buildする方法)2022/03/25 21:02:18
- [Javascript] Node.jsをインストールしてReactを使う方法2022/03/23 18:01:34
- [Java] 63. Spring bootでcronスケジューラとComponentアノテーション2022/03/16 18:57:30
- [Java] 62. Spring bootでWeb-Filterを設定する方法(Spring Security)2022/03/15 22:16:37
- [Java] JWT(Json Web Token)を発行、確認する方法2022/03/14 19:12:58
- [Java] 61. Spring bootでRedisデータベースを利用してセッションクラスタリング設定する方法2022/03/01 18:20:52
- [Java] 60. Spring bootでApacheの連結とロードバランシングを設定する方法2022/02/28 18:45:48
- [Java] 59. Spring bootのJPAでEntityManagerを使い方2022/02/25 18:27:48
- [Java] 58. EclipseでSpring bootのJPAを設定する方法2022/02/23 18:11:10
- [Java] 57. EclipseでSpring bootを設定する方法2022/02/22 19:04:49
- [Python] Redisデータベースに接続して使い方2022/02/21 18:23:49
- [Java] Redisデータベースを接続して使い方(Jedisライブラリ)2022/02/16 18:13:17
- [C#] Redisのデータベースを接続して使い方2022/02/15 18:46:09
- [CentOS] Redisデータベースをインストールする方法とコマンドを使い方2022/02/14 18:33:07