[Java] Jsoupを利用してXMLファイル(HTML)を扱う方法
こんにちは。明月です。
この投稿はJavaでJsoupを利用してXMLファイル(HTML)を扱う方法に関する説明です。
プロジェクトを作成するとXMLファイルをよく使います。特にウェブの場合は画面デザインはHTML形式で作成します。
XMLの形式はタグが開く、閉めるの構造でアトリビュートやデータになっています。XMLを探索する方法は様々の方法がありますが、最近はJqueryのsizzleエンジンでCSSSelectorでタグを探索してデータを取得する方法をよく使っています。
でもJqueryはJavaのライブラリではなく、Javascriptのライブラリです。
JavaにはJsoupというライブラリがあります。 JqueryのCSSSelectorと同じ方法で探索が可能です。
Jsoupを使うためにはmavenを利用してライブラリをダウンロードしなければならないです。
Repository - https://mvnrepository.com/artifact/org.jsoup/jsoup/1.12.1
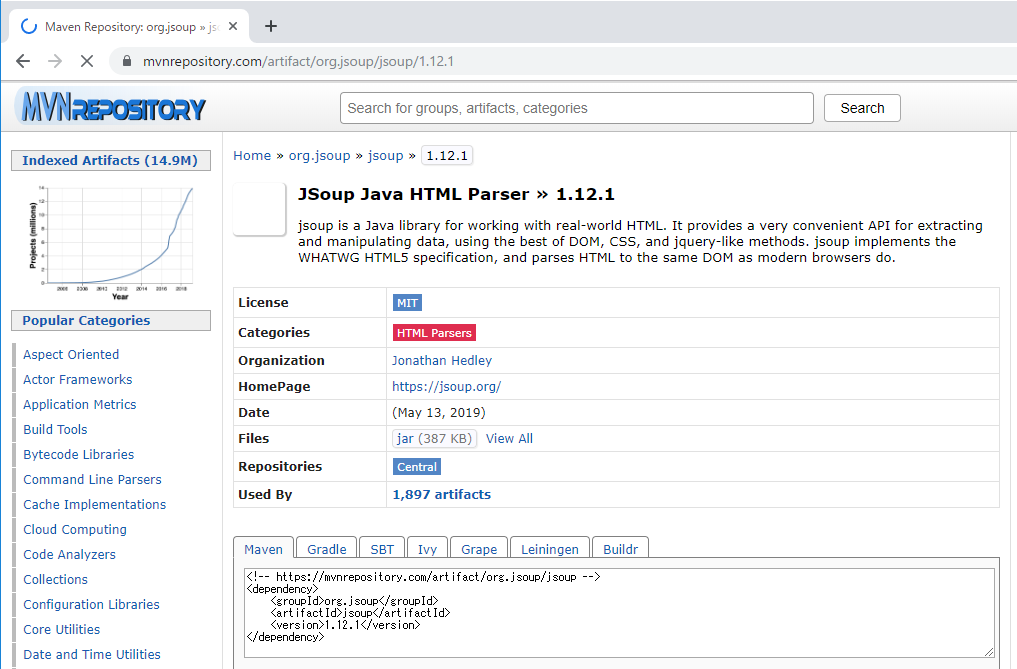
<!-- https://mvnrepository.com/artifact/org.jsoup/jsoup -->
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.12.1</version>
</dependency>
XMLを探索テストをするためにこのブログのRSSファイルを利用しましょう。
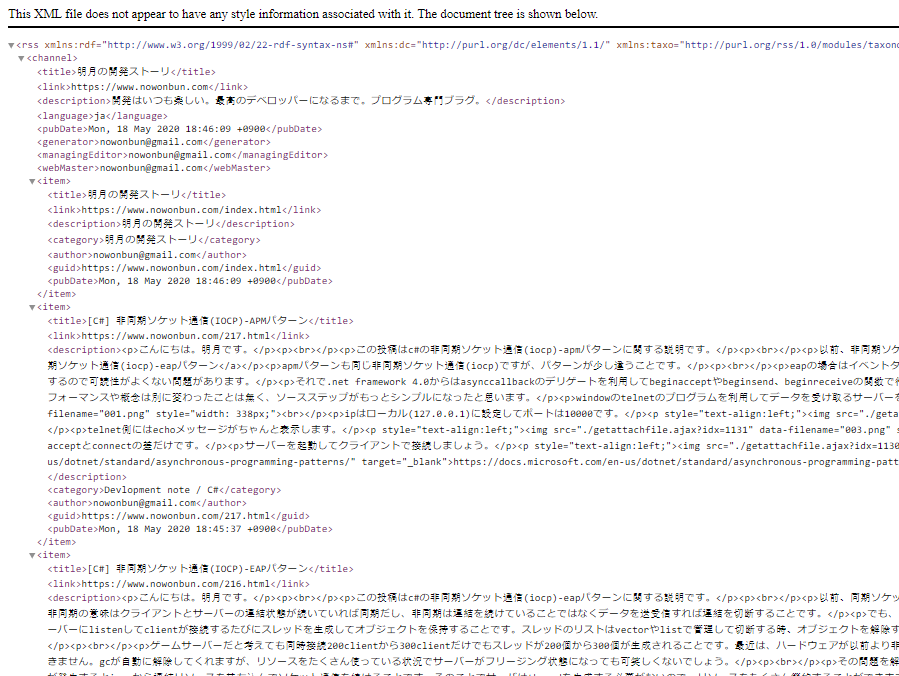
link - https://www.nowonbun.com/rss
上の例でchannel->item->title->をコンソールに出力しましょう。
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import org.jsoup.Connection;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class JsoupTest {
// HttpURLConnectionを利用してXMLデータを取得する関数
private static String getXml() {
try {
// URL生成
URL uri = new URL("https://www.nowonbun.com/rss");
// HttpURLConnectionでサーバーに接続する。
HttpURLConnection connection = (HttpURLConnection) uri.openConnection();
// ストリームを取得する。
try (BufferedReader input = new BufferedReader(new InputStreamReader(connection.getInputStream()))) {
// バッファ
String line;
StringBuffer buffer = new StringBuffer();
while ((line = input.readLine()) != null) {
buffer.append(line);
}
// データを返却する。
return buffer.toString();
}
} catch (Throwable e) {
e.printStackTrace();
return null;
}
}
// 実行関数
public static void main(String[] args) {
try {
// Jsoupのconnectでも取得可能が、Httpヘッダのcontent typeがapplication/xmlないのでエラーが発生する。
//Connection conn = Jsoup.connect("https://www.nowonbun.com/rss");
//Document doc = conn.get();
// HttpURLConnectionを利用してXMLデータを取得する。
Document doc = Jsoup.parse(getXml());
// itemタグを探索する。
Elements eles = doc.select("item");
// サブタグでタグ名がtitleを探索する。
for (Element ele : eles) {
Elements subnode = ele.select("title");
// ノード値をコンソールに出力する。
System.out.println(subnode.text());
}
} catch (Throwable e) {
e.printStackTrace();
}
}
}
上の例はHttpURLConnectionを利用してデータを取得しました。自分のブログは普通のウェブホスティングではないので、ヘッダーが正常に表示されません。そのため、Jsoup.connectを使うとエラーが発生します。

StringデータをDocumentタイプに生成します。 select関数を使って探索を開始します。
結果はitemのtitleは各投稿のタイトルなのでコンソールに出力します。
上の例はXMLを利用しましたが、Htmlファイルも探索ができます。
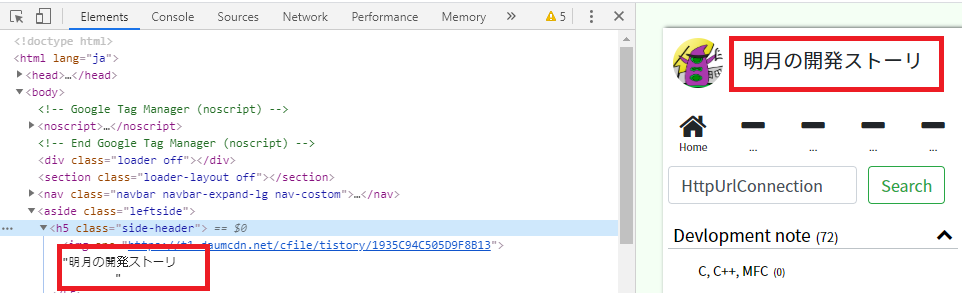
ブログの名を取得しましょう。
import org.jsoup.Connection;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.select.Elements;
public class JsoupTest {
// 実行関数
public static void main(String[] args) {
try {
// www.nowonbun.com/1.htmlのページを取得する。
Connection conn = Jsoup.connect("https://www.nowonbun.com/1.html");
// htmlを取得してDOcumentクラスを生成する。
Document doc = conn.get();
// タグのClass名で探索する。
Elements ele = doc.select(".side-header");
// コンソールに出力する。
System.out.println(ele.text());
} catch (Throwable e) {
e.printStackTrace();
}
}
}

Htmlファイルも取得してタグのclassで探索します。
結果はブログの名がよく出力されました。
ここまでJavaでJsoupを利用してXMLファイル(HTML)を扱う方法に関する説明でした。
ご不明なところや間違いところがあればコメントしてください。
- [Java] JWT(Json Web Token)を発行、確認する方法2022/03/14 19:12:58
- [Java] Redisデータベースを接続して使い方(Jedisライブラリ)2022/02/16 18:13:17
- [Java] WebSocketでチャット履歴をローディングする方法2021/06/15 18:34:45
- [Java] WebSocketを利用してユーザ(サイト運用者)が他のユーザとチャットする方法2021/06/15 17:20:08
- [Java] HttpConnectionを利用してウェブページを取得する方法2020/05/20 23:53:24
- [Java] Jsoupを利用してXMLファイル(HTML)を扱う方法2020/05/19 19:32:21
- [Java] 日付フォーマット(SimpleDateFormat)を使う方法2020/03/25 00:36:53
- [Java] サーブレット(Servlet)の環境でファイルアップロード(プログレスバーでファイルアップロード状態を表示する方法)する方法2020/03/24 00:48:21
- [Java] Spring環境でファイルアップロード(プログレスバーでファイルアップロード状態を表示する方法)する方法2020/03/22 23:15:12
- [Java] FTPに接続してファイルをダウンロード、アップロードする方法(FTPClient)2020/03/20 02:44:36
- [Java] JSPのSpring環境でschedulerのcronを使う方法2020/03/18 00:24:32
- [Java] POIを利用してExcelを扱う方法2020/03/17 01:48:00
- [Java] PDFを出力する方法(itextpdf)2020/03/13 00:47:31
- check2024/04/10 19:03:53
- [Java] 64.Spring bootとReactを連結する方法(Buildする方法)2022/03/25 21:02:18
- [Javascript] Node.jsをインストールしてReactを使う方法2022/03/23 18:01:34
- [Java] 63. Spring bootでcronスケジューラとComponentアノテーション2022/03/16 18:57:30
- [Java] 62. Spring bootでWeb-Filterを設定する方法(Spring Security)2022/03/15 22:16:37
- [Java] JWT(Json Web Token)を発行、確認する方法2022/03/14 19:12:58
- [Java] 61. Spring bootでRedisデータベースを利用してセッションクラスタリング設定する方法2022/03/01 18:20:52
- [Java] 60. Spring bootでApacheの連結とロードバランシングを設定する方法2022/02/28 18:45:48
- [Java] 59. Spring bootのJPAでEntityManagerを使い方2022/02/25 18:27:48
- [Java] 58. EclipseでSpring bootのJPAを設定する方法2022/02/23 18:11:10
- [Java] 57. EclipseでSpring bootを設定する方法2022/02/22 19:04:49
- [Python] Redisデータベースに接続して使い方2022/02/21 18:23:49
- [Java] Redisデータベースを接続して使い方(Jedisライブラリ)2022/02/16 18:13:17
- [C#] Redisのデータベースを接続して使い方2022/02/15 18:46:09
- [CentOS] Redisデータベースをインストールする方法とコマンドを使い方2022/02/14 18:33:07